With data lakes becoming popular, and Azure Data Lake Store (ADLS) Gen2 being used for many of them, a common question I am asked about is “How can I access data in ADLS Gen2 instead of a copy of the data in another product (i.e. Azure SQL Data Warehouse)?”. The benefits of accessing ADLS Gen2 directly is less ETL, less cost, to see if the data in the data lake has value before making it part of ETL, for a one-time report, for a data scientist who wants to use the data to train a model, or for using a compute solution that points to ADLS Gen2 to clean your data.
While these are all valid reasons, you still want to have a relational database (see Is the traditional data warehouse dead?). The trade-off in accessing data directly in ADLS Gen2 is slower performance, limited concurrency, limited data security (no row-level, column-level, dynamic data masking, etc) and the difficulty in accessing it compared to accessing a relational database.
Since ADLS Gen2 is just storage, you need other technologies to copy data to it or to read data in it. Here are some of the options:
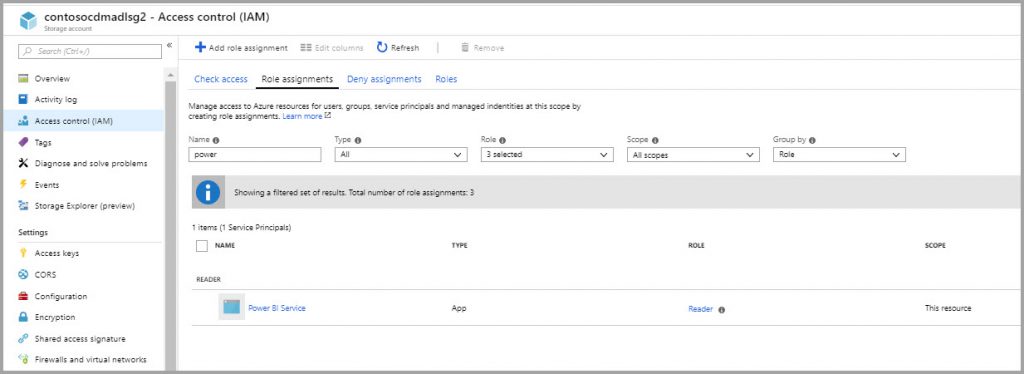
- Power BI can access it directly for reporting (in beta) or via dataflows (in preview) which allows you to copy and clean data from a source system to ADLS Gen2 (see Connect Azure Data Lake Storage Gen2 for dataflow storage (Preview)). If you get an “Access to the resource is forbidden” error when trying to read the data in Power BI, go to the ADLS Gen2 storage account on the Azure portal, choose Access control, “Add a role Assignment”, and add “Storage Blob Data Owner” (you will only get this error if, when accessing ADLS Gen2 via Get Data in Power BI, you sign in with your username – you won’t get the error if you use Access Key). Also, when importing into Power BI, make sure to choose “Combine & Transform Data” or “Combine & Load”. Note that trying to read Parquet format is not supported – a work around is you can use a Spark connector to a Databricks cluster which has imported the Parquet files
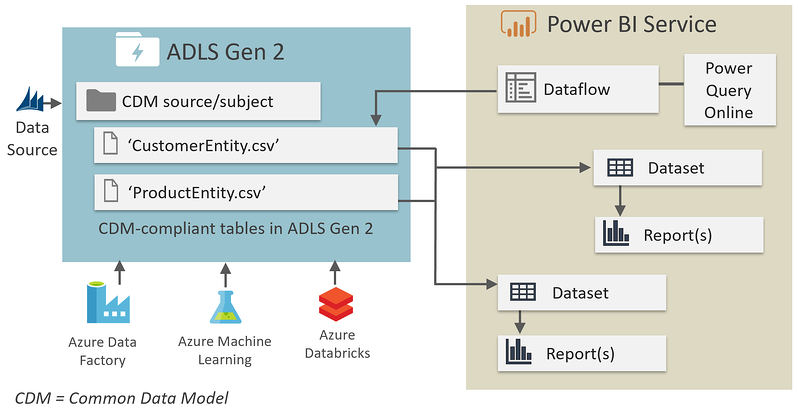
- PolyBase in SQL Data Warehouse (SQL DW). PolyBase allows the use of T-SQL. There is no pushdown computation support, so PolyBase is mostly used for data loading from ADLS Gen2 (see Load data from Azure Data Lake Storage to SQL Data Warehouse)
- PolyBase in SQL Server 2016/SQL Server 2017. Pushdown computation support is only supported when using Hadoop (Hortonworks or Cloudera). Note that PolyBase in SQL Server 2016/2017 only supports Hadoop, Blob Storage, and ADLS Gen1 (NOT ALDS Gen2), and SQL Database does not support PolyBase at all
- SQL Server 2019 CTP 2.0 introduces new connectors for PolyBase, including SQL Server, Oracle, Teradata, and MongoDB, all of which support pushdown computation. SQL Server 2019 also introduces a new feature called big data clusters (BDC), which has a special feature called ‘HDFS tiering’ that allow you to mount a directory from ADLS Gen2 as a virtual directory in the HDFS inside of the big data cluster. Then you can create an external table over that HDFS directory and query it from the SQL Server master instance in the big data cluster here. You can only do this with BDC. Other than that there is no support for ADLS Gen2 in PolyBase yet. For more information, see the PolyBase documentation for SQL Server 2019 CTP 2.0
- Azure Databricks via Spark SQL, Hive, Python, Scala, or R. Accessing ADLS Gen2 with Databricks is a bit of a pain. For help, see the official docs and these blogs: Access to Azure Data Lake Storage Gen 2 from Databricks Part 1: Quick & Dirty, Avoiding error 403 (“request not authorized”) when accessing ADLS Gen 2 from Azure Databricks while using a Service Principal, Analyzing Data in Azure Data Lake Storage Gen 2 using Databricks and the video Creating a Connection to Azure Data Lake Gen 2 with Azure Databricks
- Azure Data Factory supports ADLS Gen2 as one of its many data sources. See Copy data to or from Azure Data Lake Storage Gen2 using Azure Data Factory
- Azure HDInsight supports ADLS Gen2 and is available as a storage option for almost all Azure HDInsight cluster types as both a default and an additional storage account. See Use Azure Data Lake Storage Gen2 with Azure HDInsight clusters
- Azure Data Explorer (ADX). To query, see Query data in Azure Data Lake using Azure Data Explorer (Preview) or execute a query that writes to ADLS Gen2
- HDInsight with Hive or Pig or MapReduce. See Use Azure Data Lake Storage Gen2 with Azure HDInsight clusters
- Hortonworks (see Configuring access to ADLS Gen2) or Cloudera (see Configuring ADLS Gen2 Connectivity) which are both available in the Azure Marketplace
The main thing to consider when determining the technology to use to access data in ADLS Gen2 is the skillset of the end user and the ease of use of the tool. T-SQL is easiest, but currently the Microsoft products have some limitations on when T-SQL can be used.